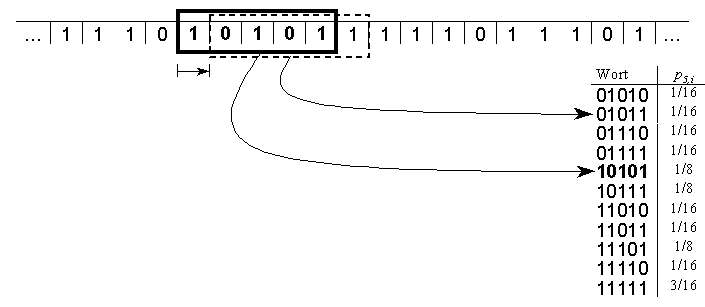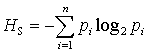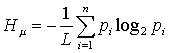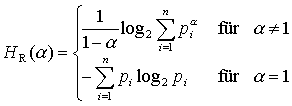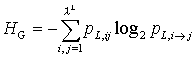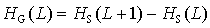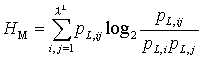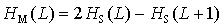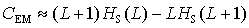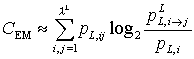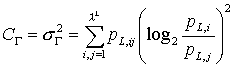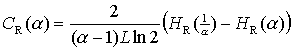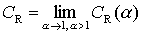Dieser Artikel wurde aus der
Dissertation des
Autors extrahiert.
Er gibt eine knappe Übersicht zur Berechnung einiger
Maße für Information und Komplexität aus praktischer Sicht.
Weitere Details und theoretische Hintergründe müssen in der Literatur
nachgelesen werden und sind in der
Dissertation zusammengestellt.
Die Berechnung von Information und Komplexität beschränkt sich hier
auf eindimensionale äquidistante Zeitreihen.
Der Wertebereich einer Zeitreihe ist dabei auf
die Symbole eines kleinen Alphabets beschränkt.
Anstelle von Zeitreihen spricht man daher auch von Symbolfolgen.
Beispiele für Alphabete sind etwa:
binär, zwei Symbole: Das kleinste Alphabet, z. B. 0 und 1 (Computercode)
quaternär, vier Symbole: Ein DNA-Strang kann beispielsweise als eine
Symbolsequenz über die Symbole A, C, G, T dargestellt werden, da jeder
Strang der Doppelhelix aus den Basen Adenin, Cytosin, Guanin und Thymin
aufgebaut ist.
Natürlich kann auch ein Text aus einem Buch, einer Zeitung, etc.
als Symbolfolge angesehen werden. Das Alphabet ist dann das bekannte
Alphabet der jeweiligen Sprache mit den Sonderzeichen und Ziffern.
Eine Zeitreihe, die nicht als Symbolfolge vorliegt kann z. B. durch
Partitionierung ihres Wertebereiches in eine Symbolfolge umgewandelt werden.
Dabei können bestimmte Bereiche des Wertebereiches einem Symbol
zugeordnet werden. Beliebt ist z. B. die Zuordnung aller Werte unterhalb
des Medians der Zeitreihe zu dem Symbol '0' und aller Werte darüber
zu dem Symbol '1'. Auf diese Weise entsteht eine binäre Symbolsequenz
mit etwa gleich vielen Nullen und Einsen.
Die Berechnung von Information und Komplexität erfolgt über
die Verteilungen von Teilsequenzen der Symbolfolge – der sogenannten
Wörter. Dazu wird zunächst eine Wortlänge L festgelegt.
Die Wörter der Länge L werden auch
L-Wörter genannt.
Von jedem dieser L-Wörter wird dann die relative Häufigkeit
pL,i in der Symbolfolge ermittelt.
Darüber hinaus werden bei manchen Maßen auch noch die
Übergangshäufigkeiten zwischen Wörtern berücksichtigt.
In der Abbildung liegt eine binäre Symbolfolge vor.
Ein Fenster der Länge 5 wird jeweils um ein Symbol verschoben über
die Sequenz geschoben. Dabei wird eine Liste aller verschiedenen 5-Wörter
erstellt. Die relative Häufigkeit jedes dieser Wörter wird ebenfalls
in der Liste notiert.
Hinweis: Die Maße für Information und Komplexität
sind über Wahrscheinlichkeits-Verteilungen definiert. Diese sind
jedoch bei praktischen Daten (Meßreihen, Texte, DNA, etc.) unbekannt.
Bei der Berechnung der Maße müssen in diesem Fall die
Wahrscheinlichkeiten durch die relativen
Häufigkeiten approximiert werden.
In der Notation soll hier nicht zwischen
relativen Häufigkeiten und Wahrscheinlichkeiten unterschieden werden.
In den Formeln werden die folgenden Größen und Symbole verwendet:
L
Wortlänge
i
Index des i-ten L-Wortes, L-Wort i
λ
Anzahl der Symbole eines Alphabets, Alphabetgröße
n
Anzahl der der verschiedenen L-Wörter,
maximal λL
pi, pL,i
Wahrscheinlichkeit für das Auftreten des i-ten L-Wortes
pL,ij
Wahrscheinlichkeit für das gleichzeitige Auftreten des i-ten
und des j-ten L-Wortes, wobei das Wort j ein auf das
Wort i überlappend folgendes Wort ist. Die beiden Wörter
haben daher L-1 Symbole gemeinsam.
pi, pL,i→j
Wahrscheinlichkeit für das Auftreten des j-ten L-Wortes
unter der Bedingung der vorherigen Beobachtung des i-ten L-Wortes
Im Zusammenhang mit Untersuchungen zur Nachrichtenübertragung in Telefonleitungen
definierte Shannon (1948)
das historisch erste Maß für Information - die Shannon Entropie:
Der Informationsbegriff von Shannon bewertet nicht den semantischen Inhalt oder
die Bedeutung einer Nachricht, sondern dessen Unvorhersagbarkeit
(Zufälligkeit, Unordnung).
Eine Nachricht ist umso informationsreicher, je unsicherer wir über ihren
syntaktischen Inhalt sind. Die Shannon-Entropie ist das klassische Maß
für Information und wird durch die folgenden Informationsmaße
verfeinert. Der Name "Entropie" geht auf die analoge Bedeutung der Formel
in der Thermodynamik zurück.
Die Shannon-Entropie nimmt linear mit der Wortlänge zu.
Durch Normierung mit der Wortlänge erhält man den
gleichen Informationsbegriff aber unabhängig von der Wortlänge.
Dieses Maß wird Metrische Entropie genannt:
Durch den Parameter α können
seltene oder häufige Wörter unterschiedlich gewichtet werden.
Für α > 1 werden
die höheren Wahrscheinlichkeiten stärker gewichtet als die
niedrigeren. Für α < 1 werden
umgekehrt die niedrigeren Wahrscheinlichkeiten aufgewertet.
Der mittlere Gewinn an Information, der durch die Kenntnis des auf
ein L-Wort folgenden Symbols erhalten wird, definiert
ein weiteres wichtiges Maß für Information. Den mittleren Informationsgewinn.
Die kompakte Formel benötigt weniger Rechenzeit und ist numerisch stabiler.
Dieser Informationsbegriff läßt sich anhand eines Beispiels für
ein Wort leicht veranschaulichen: Wenn in diesem Text die Buchstabenfolge
„Info” beobachtet wird, dann ist der darauffolgende Buchstabe mit
Sicherheit ein „r”. Durch die Kenntnis des nachfolgenden Buchstabens
gewinnen wir in diesem Fall keine Information dazu.
Hätten wir die Folge „die_” beobachtet, dann ist es schwer den
nächsten Buchstaben vorherzusagen. Nahezu jeder Buchstabe ist möglich,
da es sich um den ersten Buchstaben eines beliebigen Wortes der deutschen
Sprache handelt. Durch die Kenntnis des nächsten
Buchstabens gewinnen wir hier also viel Information hinzu.
Der mittlere Informationsgewinn HG gibt an, wieviel
zusätzliche Information das nächste Zeichen einer Symbolfolge im Mittel bringt.
Die mittlere wechselseitige Information gibt an, wieviel Information
im Mittel in der Abhängigkeit (Korreliertheit) von zwei aufeinanderfolgenden
Wörten enthalten ist. Sie wird nach
Wackerbauer et al. (1994) wie folgt
definiert:
Die minimale Gesamtmenge an Information, die gespeichert werden muss,
um zu jeder Zeit eine optimale Vorhersage über das nächste
Symbol liefern zu können wird nach
Grassberger (1986, S. 920)
mit der Effektiven Maßkomplexität angegeben.
Diese Größe ist als Grenzwert definiert
und kann durch die Formel
Beim Übergang des L-Wortes i in das L-Wort j
ist mit dem neuen Symbol ein Informationsgewinn verbunden. Dies führte
zur Definition des Mittleren Informationsgewinns.
Gleichzeitig ist mit dem Vergessen des ersten Symbols von Wort i
ein Informationsverlust verbunden. Im Mittel über die gesamte Symbolfolge
heben sich Informationsgewinn und -verlust auf. Die Schwankung zwischen
diesen beiden Größen wird mit der Fluktuationskomplexität
nach Bates & Shepard (1993)
gemessen.
Im Beispiel zum Informationsgewinn
wurde das 4-Wort „Info” betrachtet, auf das das 4-Wort
„nfor” folgt. Der Informationsgewinn durch das
„r” ist Null in diesem Text, während der
Informationsverlust durch das Vergessen des „I”
höher ist. Denn „nfor” kommt in diesem Text
auch in den Wörtern „Anforderungen” und
„informativ” mit kleinem „i” vor.
Je mehr diese Bilanz aus
Informationsgewinn und -verlust in dem untersuchten Text schwankt,
desto komplexer ist der Text im Sinne der Fluktuationskomplexität.
Nach einer mündlichen Empfehlung von
Prof. Dr. Jürgen Kurths
können die Differenzen von Rényi-Entropien konjugierter
Ordnungen als Maß für Komplexität verstanden werden.
Dies führt zu einer eigenen Definition eines Komplexitätsmaßes.
Die Rényi-Komplexität CR(α)
der Ordnung α > 1 einer Verteilung von L-Wörtern sei:
Der Normierungsfaktor schafft Unabhängigkeit von der Wortlänge
und hebt die Nullstelle für
α → 1 auf.
Untersuchungen zeigten, dass CR nur für
α ≈ 1 spezifisch
im Sinne eines Maßes für Komplexität ist.
Daher sei die Rényi-Komplexität definiert als
Es zeigte sich, dass eine gute numerisch stabile Approximation
dieser Größe durch CR(1.0001)
erreicht wird.
Die Rényi-Komplexität liefert eine Bewertung von Dynamik,
die qualitativ mit der Bewertung von Dynamik der Fluktuationskomplexität
vergleichbar ist. Die Rényi-Komplexität erwies sich jedoch
als die stabilere Alternative.
Wie bereits bei der Notation erwähnt, sind
die Informations- und Komplexitätsmaße auf den
Wahrscheinlichkeitsverteilungen der L-Wörter definiert.
Diese sind aber bei praktischen Daten unbekannt und können
nur aus den relativen Häufigkeiten geschätzt werden.
Es ist leicht einzusehen, dass diese Schätzung bei großen
Wortlängen im Vergleich zur Anzahl der Datenpunkte unmöglich sein kann
und zu erheblichen Fehlern in den Maßen führt.
Bei N Datenpunkten gibt es N−L+1 Wörter.
Theoretisch sind maximal λL verschiedene
Wörter möglich. Daher können bereits bei kleinen
Wortlängen nicht mehr alle theoretisch möglichen Wörter
(genügend oft) beobachtet werden.
Zur Erfassung der dynamischen Struktur der Daten sind jedoch
meist hohe Wortlängen erforderlich.
Damit wird die Wortlänge auf den maximalen Wert fixiert, der noch
eine hinreichend genaue Berechnung eines Maßes erlaubt.
Ein solcher Wert kann jedoch nicht für alle Verteilungen ermittelt werden.
Es kann jedoch eine Abschätzung für den schlimmsten Fall gemacht
werden. Dies ist der Fall gleichverteilter Zufallsfolgen, da hier stets
alle Wörter möglich sind und sich der Datenvorrat somit am schnellsten
erschöpft. In diesem Fall kann die Wahrscheinlichkeit ein Wort gar nicht,
einmal, zweimal etc. zu beobachten gemäß einer Binomial-Verteilung
angegeben werden. Damit kann für jedes Informations- und
Komplexitätsmaß ein Erwartungswert in Abhängigkeit von der
Datenmenge, Wortlänge und Alphabetgröße berechnet werden.
Die entsprechenden
Formeln sind in der Dissertation hergeleitet.
Der theoretische Wert der Maße ist in diesem Fall außerdem bekannt.
Somit kann eine Toleranzbedingung für die Abweichung (relative Genauigkeit)
des Erwartungswertes vom theoretischen Wert aufgestellt werden.
Zu gegebener maximaler Genauigkeit kann damit für jede
Alphabetgröße und Wortlänge die erforderliche
Datenmenge bestimmt werden. Dies erfordert einen erheblichen
Rechenaufwand, da sich die Gleichungen analytisch nicht lösen
lassen.
Entsprechende Rechnungen wurden in der Dissertation
für einge relevante Parameterkombinationen durchgeführt.
D. h. für 1 % und 2 % relative Genauigkeit,
binäre, ternäre und quaternäre Alphabete und alle
Wortlängen, bis mehr als 1000000 Datenpunkte erforderlich wurden.
Die Ergebnisse werden hier durch den JavaScript Rechner
zugänglich gemacht.
Mit Hilfe des Javascript Rechners können Sie ermittlen,
welche Wortlänge bei einer gegebenen Anzahl von Datenpunkten
noch erlaubt ist, oder wieviele Datenpunkte für eine
gegebene Wortlänge erforderlich ist.
Der Rechner berücksichtigt den schlimmsten
(Daten-intensivsten) Fall. Beachten Sie daher bitte Folgendes:
Beachten Sie die Empfehlungen des Rechners, wenn Sie hochinformative
Daten untersuchen, z. B. DNA-Sequenzen, Niederschlag, Zufallsfolgen, irrationale Zahlen.
Beachten Sie die Empfehlungen des Rechners ebenfalls, wenn Sie
unterschiedliche — also auch hochinformative — Datensequenzen
miteinander vergleichen wollen.
Sie können größere Wortlängen und Alphabete bei
geringeren Datenmengen verwenden, wenn sie mit Sicherheit nur mittel-
oder gering-informative Daten untersuchen wollen.
Dies ist z. B. bei Texten, Büchern, etc. der Fall.
Machen Sie dazu Ihre eigenen Datenmenge / Wortlänge Untersuchungen.
Die Angaben des Rechners beziehen sich auf die folgenden Formeln:
Shannon-Entropie: (1), (2) und (3) mit α ≈ 1;
Informationsgewinn: (4) und (5);
Wechselseitige Information: diff. (7), kmpkt. (6);
Effektive Maßkomplexität: (8) und (9);
Fluktuationskomplexität: (10);
Rényi-Komplexität: (11) mit α = 1.0001.
Bates, JE; Shepard, HK (1993): Measuring complexity using information fluctuation.
Physics Letters A, 172: 416–425.
Grassberger, P (1986): Toward a Quantitative Theory of Self-Generated Complexity.
International Journal of Theoretical Physics, 25 (9): 907–938.
Rényi, A (1960): Some Fundamental Questions of Information Theory.
In: Pál Turán (Hrsg.): Selected Papers of Alfréd
Rényi. Vol. 2: 1956 — 1961. Budapest: Akadémiai
Kiadó, 1976: 526–552.
Rényi, A (1961): On measures of entropy and information.
In: Pál Turán (Hrsg.): Selected Papers of Alfréd
Rényi. Vol. 2: 1956 — 1961. Budapest: Akadémiai
Kiadó, 1976: 565–580.
Shannon, CE (1948): A Mathematical Theory of Communication.
Bell System Technical Journal, 27: 379–423.
Wackerbauer, R; Witt, A; Atmanspacher, H; Kurths, J; Scheingraber, H (1994):
A Comparative Classification of Complexity Measures.
Chaos, Solitons & Fractals, 4: 133–173.
Eine ausführlichere Literaturliste findet sich in der Dissertation.